¿Qué es la computación de borde?
La computación de borde es un modelo de computación descentralizado en el que el procesamiento de datos se realiza en el punto de origen o cerca de él, en lugar de transmitirse a un centro de datos centralizado o a un entorno de nube. Este enfoque contrasta con las arquitecturas de computación tradicionales, que dependen en gran medida del procesamiento centralizado, a menudo ubicado lejos de los dispositivos que generan los datos.
En un entorno de computación perimetral, el análisis de datos y la capacidad de respuesta del sistema se producen mucho más cerca del lugar donde se generan los datos, ya sea que se recopilen de sistemas IoT, sensores perimetrales IoT o sistemas de control industrial. Este enfoque local de la computación permite que los sistemas operen con mayor autonomía, lo que les permite interpretar y actuar sobre los datos sin depender de una comunicación constante con una nube o centro de datos central.
La computación de borde está estrechamente relacionada con el concepto de borde inteligente , donde los dispositivos en el extremo de la red procesan y analizan datos en tiempo real, lo que permite una toma de decisiones más inteligente y rápida. Estas aplicaciones suelen englobarse dentro de las aplicaciones de IoT , diseñadas para aprovechar la computación localizada y mejorar la capacidad de respuesta.
El auge de la computación perimetral refleja la creciente necesidad de gestionar el enorme flujo de datos generados por dispositivos distribuidos en tiempo real. A medida que los entornos digitales se vuelven más complejos y geográficamente dispersos, las arquitecturas centralizadas convencionales suelen tener dificultades para satisfacer las demandas de rendimiento y escalabilidad. La computación perimetral aborda este desafío distribuyendo la capacidad de procesamiento en distintos puntos de la red, lo que permite obtener información más rápidamente y un comportamiento del sistema más adaptable.
Este modelo descentralizado representa un cambio fundamental en la forma en que las organizaciones desarrollan e implementan aplicaciones modernas. En lugar de centralizar todas las tareas de procesamiento, la computación perimetral potencia las operaciones locales y respalda una infraestructura escalable y resiliente en diversos sectores, desde la manufactura y la logística hasta la atención médica y las ciudades inteligentes, a menudo utilizando sistemas intermedios como pasarelas IoT para conectar los dispositivos perimetrales a redes más amplias.
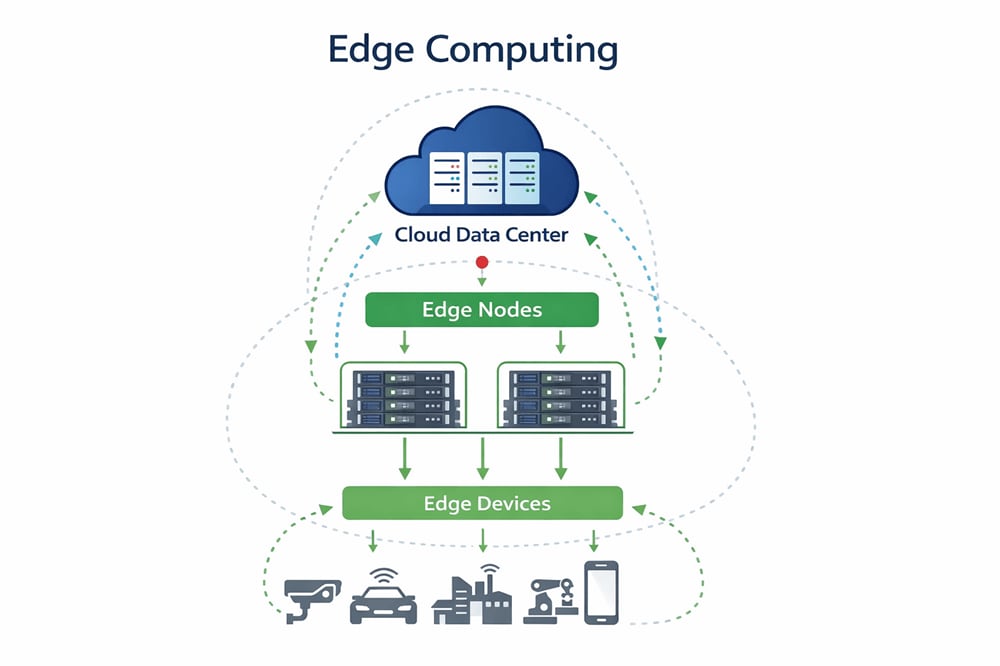
Cómo funciona la computación de borde
La computación perimetral funciona trasladando tareas informáticas clave, como el análisis y el procesamiento de datos, desde centros de datos centralizados a ubicaciones distribuidas físicamente más cercanas al origen de los datos. Este cambio no se limita a la geografía, sino que implica la reestructuración de la arquitectura para dar soporte a operaciones críticas en tiempo real, reducir la dependencia de la red y permitir la toma de decisiones en tiempo real en el origen. Los entornos perimetrales suelen constar de un sistema por capas que incluye dispositivos perimetrales, nodos informáticos localizados y componentes de red que se coordinan con los sistemas centrales según sea necesario.
Las soluciones avanzadas de servidores integrados desempeñan un papel crucial en el ámbito de la computación perimetral. Estos servidores están diseñados para ser energéticamente eficientes y ofrecer un rendimiento robusto, satisfaciendo las exigentes necesidades de las tareas de computación perimetral. Con un firme compromiso con la computación verde , estas soluciones buscan minimizar el impacto ambiental. Lo logran reduciendo la huella de carbono y maximizando la eficiencia operativa.
Igualmente importante, estas soluciones de servidor están diseñadas para operar de forma fiable en condiciones ambientales adversas. Esto garantiza un rendimiento constante en diversos entornos, incluso en aquellos con temperaturas extremas u otros requisitos operativos exigentes. La versatilidad y la resistencia de estos servidores los hacen ideales para una amplia gama de aplicaciones de computación perimetral.
Los sistemas de computación perimetral también suelen diseñarse teniendo en cuenta la seguridad reforzada, dado que a menudo procesan datos confidenciales fuera de los perímetros de TI tradicionales. Los controles de seguridad localizados, el cifrado y el endurecimiento del sistema son fundamentales para garantizar la integridad y la privacidad de los datos procesados en el borde de la red.
Al desplegar la capacidad de procesamiento más cerca de donde se generan los datos, la computación perimetral permite tiempos de procesamiento más rápidos, reduce la presión sobre el ancho de banda de la red y mejora la capacidad de respuesta de los servicios y dispositivos digitales.
Computación en el borde, en la nube y en la niebla
Si bien la computación perimetral, en la nube y en la niebla están relacionadas con la forma y el lugar donde se procesan los datos, cada una representa un enfoque distinto de la arquitectura informática con diferentes aplicaciones y características de rendimiento.
La computación en la nube se basa en centros de datos centralizados, a menudo ubicados lejos del punto de generación de datos. En este modelo, los datos se transmiten a través de una red (normalmente internet) para ser procesados, almacenados y gestionados por proveedores de servicios en la nube. Este enfoque ofrece escalabilidad y control centralizado, pero puede generar latencia y limitaciones de ancho de banda, especialmente para aplicaciones en tiempo real o de alto volumen.
En cambio, la computación de borde procesa los datos localmente o cerca de su origen. Este modelo reduce la distancia que deben recorrer los datos y minimiza la latencia al analizar la información directamente en el dispositivo o en un nodo de borde cercano. Es ideal para casos de uso que requieren información o acciones inmediatas, como sistemas autónomos, automatización industrial o análisis de vídeo in situ.
La computación en la niebla actúa como intermediaria entre los entornos de borde y la nube. Extiende las capacidades de la nube hasta el borde mediante la introducción de una capa de computación distribuida que opera entre los dispositivos locales y la infraestructura centralizada de la nube . La computación en la niebla ayuda a gestionar tareas que requieren demasiados recursos para los dispositivos de borde, pero que son demasiado sensibles a la latencia para el procesamiento exclusivamente en la nube.
En esencia, la computación en la nube es centralizada, la computación perimetral es totalmente descentralizada y la computación en la niebla ofrece un enfoque híbrido. Cada modelo tiene su lugar según los requisitos específicos de velocidad, ancho de banda, soberanía de datos y capacidad de procesamiento.
Principales ventajas de la computación perimetral
La computación perimetral ofrece varias ventajas estratégicas y operativas que la convierten en una arquitectura atractiva para las aplicaciones modernas con uso intensivo de datos.
Una de las ventajas más significativas es la reducción de la latencia. Al procesar los datos directamente en la fuente o cerca de ella, la computación perimetral elimina la necesidad de transmitir información a larga distancia a sistemas centralizados. Esto reduce drásticamente los tiempos de respuesta, lo cual es fundamental para aplicaciones en tiempo real como vehículos autónomos, realidad aumentada, automatización industrial y diagnóstico remoto en telemedicina.
Otra ventaja clave es la eficiencia del ancho de banda. El procesamiento de datos localizado permite a los sistemas filtrar, analizar y actuar sobre los datos antes de transmitir únicamente la información esencial a las plataformas centralizadas en la nube. Esto minimiza el volumen de datos enviados a través de la red, reduciendo el uso del ancho de banda y los costos asociados, lo cual resulta especialmente valioso en entornos con conectividad limitada o costosa.
La mejora de la seguridad y la privacidad de los datos también son características inherentes a la computación perimetral. El procesamiento de datos in situ o dentro de la infraestructura local reduce la exposición de información confidencial durante la transmisión. Esto puede disminuir el riesgo de interceptación o acceso no autorizado, especialmente en sectores con estrictas normativas, como la sanidad, las finanzas y las infraestructuras críticas.
Finalmente, la computación perimetral contribuye a una mayor fiabilidad del sistema. Dado que los dispositivos y nodos perimetrales pueden operar independientemente de la nube central, pueden seguir funcionando durante interrupciones o caídas de la red. Esta resiliencia localizada garantiza la continuidad del servicio, incluso cuando se pierde temporalmente la conectividad con la infraestructura central.
Estas ventajas combinadas convierten a la computación perimetral en un enfoque potente para las organizaciones que buscan aumentar el rendimiento, reducir los riesgos operativos y brindar un mejor soporte a los entornos distribuidos.
Casos de uso y aplicaciones
La computación perimetral permite el procesamiento in situ o cerca del sitio, lo cual se ha vuelto fundamental para las industrias que requieren una toma de decisiones rápida y un control localizado. Su capacidad para acercar la potencia de cálculo a la fuente de generación de datos ha abierto nuevas oportunidades para la innovación, especialmente en entornos donde la latencia, la fiabilidad y la capacidad de respuesta son cruciales.
En la fabricación, la computación perimetral permite el mantenimiento predictivo, el control de calidad en tiempo real y la optimización de la producción mediante el análisis de datos de sensores directamente en la planta de producción. Los sistemas sanitarios utilizan capacidades perimetrales para respaldar el diagnóstico remoto, la monitorización de pacientes y la obtención de imágenes médicas en entornos donde la baja latencia es fundamental. En el comercio minorista, la infraestructura perimetral respalda los sistemas de pago inteligentes, las experiencias personalizadas del cliente y la gestión eficiente del inventario mediante el procesamiento local de datos en las tiendas.
Los vehículos autónomos dependen en gran medida de la computación perimetral para interpretar los datos de los sensores, tomar decisiones de conducción y comunicarse con la infraestructura cercana. Todo esto ocurre en tiempo real y sin depender de una conectividad constante a la nube. De manera similar, las iniciativas de ciudades inteligentes utilizan tecnologías perimetrales para gestionar los sistemas de tráfico, supervisar la infraestructura de seguridad pública y optimizar el consumo de energía a nivel local.
La computación de borde también está estrechamente ligada a la expansión de las soluciones de IoT de borde , que implican el procesamiento de datos en o cerca de los dispositivos conectados. Si bien estas aplicaciones son diversas y están en constante crecimiento, sus diferencias técnicas se abordan con mayor profundidad en una página de glosario dedicada a IoT de borde.
Como elemento clave para la computación distribuida , la arquitectura de borde permite a las organizaciones extender sus capacidades de TI al mundo físico, lo que facilita una toma de decisiones más rápida, sistemas más resilientes y modelos de implementación escalables. Desde la automatización industrial hasta la atención médica conectada y los sistemas de transporte inteligentes, la computación de borde desempeña un papel crucial en la creación de ecosistemas digitales rápidos, eficientes y adaptables en las empresas modernas.
Desafíos y consideraciones
Si bien la computación perimetral ofrece claras ventajas en velocidad, escalabilidad y eficiencia, también introduce una serie de desafíos únicos que las organizaciones deben abordar para garantizar una implementación y un funcionamiento exitosos.
Una de las principales consideraciones es la complejidad de la gestión. Con los recursos informáticos distribuidos en múltiples ubicaciones periféricas, mantener un rendimiento, seguridad y estándares de configuración consistentes puede resultar cada vez más difícil. Esto es especialmente cierto si se encuentran en entornos remotos o con limitaciones físicas. Para superar este desafío, los equipos de TI deben gestionar una amplia gama de componentes de hardware, software y redes en sitios descentralizados.
La seguridad y la protección de datos también son aspectos cruciales. Si bien el procesamiento local de datos puede reducir la exposición durante la transmisión, los dispositivos y nodos periféricos pueden ser más accesibles físicamente u operar fuera de los perímetros de seguridad tradicionales de la empresa. Esto incrementa la necesidad de una protección robusta de los puntos finales, procesos de arranque seguros y monitoreo en tiempo real para protegerse contra el acceso no autorizado o la manipulación.
La interoperabilidad y la estandarización plantean otro desafío. Los entornos de borde suelen involucrar una amplia variedad de dispositivos, plataformas y protocolos. Garantizar la compatibilidad entre estos componentes, especialmente en entornos con múltiples proveedores o sistemas heredados, puede afectar tanto los esfuerzos de integración como la escalabilidad a largo plazo.
Además, los costos de infraestructura pueden ser significativos. Si bien la computación perimetral reduce la carga sobre los centros de datos centralizados, el despliegue y mantenimiento de hardware perimetral a gran escala requiere inversión en sistemas robustos, fuentes de alimentación confiables y conectividad segura. El retorno de la inversión depende en gran medida del caso de uso, la escala de despliegue y la estrategia operativa.
Finalmente, las organizaciones deben considerar el ciclo de vida de los datos en el extremo de la red. Las decisiones sobre qué datos procesar localmente, cuáles descartar y cuáles enviar a la nube para su almacenamiento a largo plazo o análisis requieren una planificación cuidadosa y la aplicación de políticas para equilibrar el rendimiento con los requisitos regulatorios y comerciales.
Términos clave en computación de borde
Comprender los componentes básicos de la computación de borde es fundamental para entender cómo funcionan las arquitecturas distribuidas. A continuación, se presentan algunos términos importantes comúnmente asociados con los entornos de borde:
Nodo de borde
Un nodo de borde es un punto final de computación localizado que procesa o retransmite datos generados por dispositivos cercanos. Generalmente, funciona como la primera capa de procesamiento en la jerarquía de computación de borde, lo que permite el filtrado de datos en tiempo real o la toma de decisiones más cerca de la fuente.
Puerta
Una puerta de enlace funciona como un puente entre los dispositivos periféricos y las redes o sistemas centrales. Gestiona el tráfico de datos, se encarga de la traducción de protocolos y, a menudo, realiza tareas básicas de procesamiento o seguridad antes de reenviar los datos hacia arriba o hacia abajo.
Centro de microdatos
Los microcentros de datos son instalaciones compactas y autónomas que proporcionan recursos de computación, almacenamiento y redes cerca del punto de uso. Admiten aplicaciones específicas o cargas de trabajo localizadas, lo que reduce la necesidad de enviar datos a centros de datos distantes.
Dispositivo de borde
Un dispositivo de borde es cualquier punto final, como un sensor, una cámara o un controlador industrial, que genera o consume datos dentro de un entorno de computación de borde. Estos dispositivos suelen tener una capacidad de procesamiento limitada para permitir respuestas en tiempo real.
Orquestador de borde
Un orquestador de borde es una capa de software o plataforma que gestiona, implementa y supervisa las cargas de trabajo en múltiples nodos de borde. Permite el control centralizado de la infraestructura descentralizada, lo que ayuda a mantener la coherencia y la escalabilidad.
Estado latente
En la computación de borde, la latencia se refiere al retraso entre el momento en que se generan los datos y el momento en que se procesan o se actúa sobre ellos. Reducir la latencia es uno de los principales objetivos de ubicar los recursos de computación más cerca de la fuente de datos.
Procesamiento en tiempo real
Este término se refiere a la capacidad de un sistema para ingerir, analizar y procesar datos en cuestión de milisegundos. La computación perimetral permite el procesamiento en tiempo real al minimizar los retrasos en la transmisión y posibilitar el cálculo local inmediato.
Preguntas frecuentes
- ¿Cuál es la diferencia entre la computación perimetral y la computación en la nube?
Si bien tanto la computación perimetral como la computación en la nube implican el almacenamiento y procesamiento de datos, la principal diferencia radica en la ubicación. La computación en la nube centraliza el procesamiento en grandes centros de datos, a menudo ubicados lejos de los usuarios finales. En cambio, la computación perimetral procesa los datos más cerca de donde se generan. - ¿Cómo mejora la computación perimetral el IoT?
La computación perimetral complementa el IoT al permitir que los dispositivos procesen y analicen datos localmente, en lugar de enviarlos a una nube central para su procesamiento. Esto facilita una toma de decisiones más rápida, una ventaja clave para aplicaciones que requieren una respuesta inmediata, como la automatización industrial, las ciudades inteligentes o los sistemas autónomos. - ¿Es la computación perimetral más segura que la computación en la nube?
La computación perimetral puede mejorar la privacidad y la seguridad de los datos al limitar la distancia que deben recorrer los datos confidenciales, reduciendo así la exposición durante la transmisión. Sin embargo, también plantea nuevos desafíos de seguridad, como la gestión de un gran número de puntos finales distribuidos. Tanto los entornos perimetrales como los de la nube requieren estrategias de seguridad integrales y específicas para cada contexto. - ¿Por qué es importante la computación perimetral para el 5G?
La computación perimetral es esencial para las redes 5G porque ayuda a reducir la latencia. Dado que 5G permite una transmisión de datos más rápida, la infraestructura perimetral garantiza que el procesamiento pueda mantenerse al ritmo, especialmente para aplicaciones móviles y que requieren un gran ancho de banda. - ¿Cuáles son algunos ejemplos de computación perimetral en la vida real?
Ejemplos reales de computación perimetral incluyen vehículos autónomos que procesan datos de sensores en tiempo real, tiendas minoristas que utilizan análisis internos para comprender el comportamiento del cliente y plantas industriales que implementan sistemas de mantenimiento predictivo. Estos escenarios requieren un procesamiento de datos inmediato sin depender de centros de datos remotos.