Supermicro 数据工程解决方案
启用人工智能并从数据中生成洞察力
Supermicro 利用数据构建人工智能的解决方案
应对人工智能的数据挑战
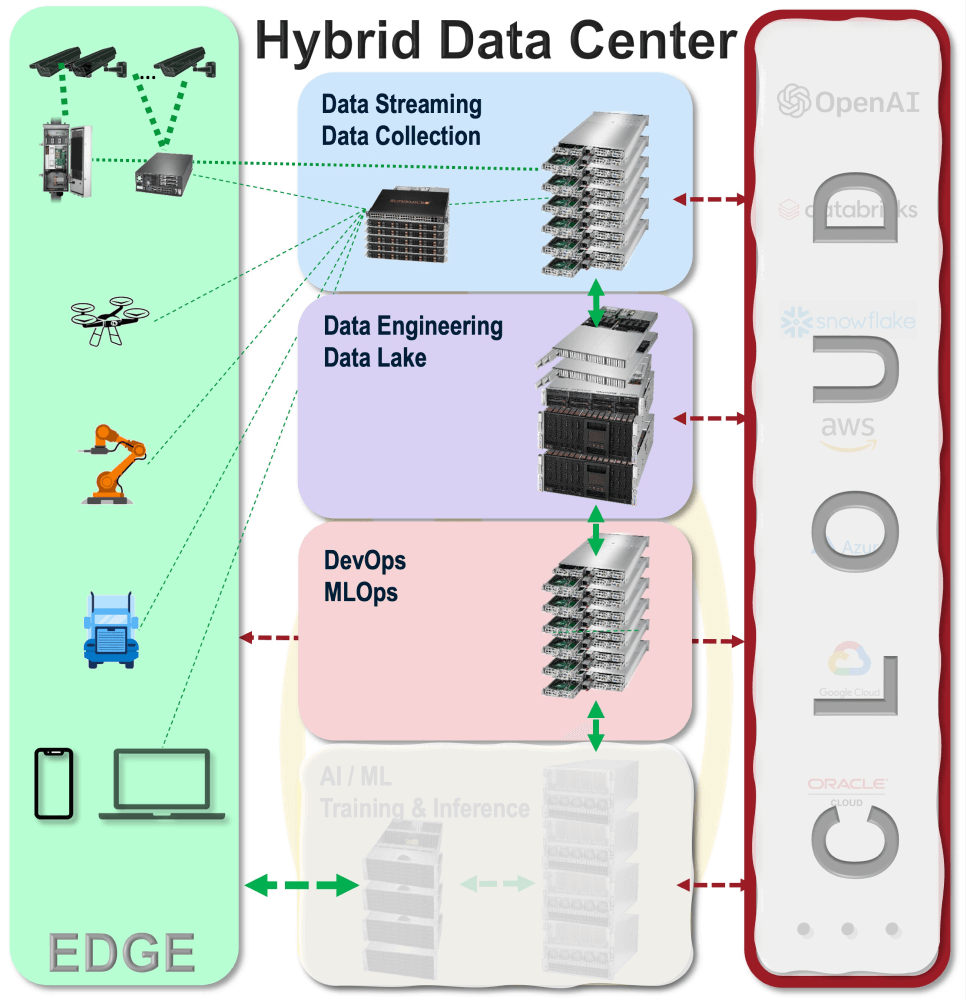
对新数据进行人工智能培训和推理是为客户创造新服务和优化业务运营的关键。随着传感器的低成本化以及通过互联网与客户进行越来越多的社交互动,企业可以从每天不断增加的数据量中获得巨大优势,从而改进人工智能系统。在实施尊重客户数据隐私的数据流系统时,以下关键功能可为人工智能训练和推理提供支持:
- 数据流管理从边缘设备和互联网收集的数据
- 将数据流传输到运行 Apache Kafka、NiFi 和 Flink 的系统中
- 对从数据湖中提取的数据进行数据工程设计,为人工智能工作流程建立数据管道
- 将数据导入不同人工智能工作流程的数据管道
- 使用 Apache Spark 进行数据提取和转换
- 使用 Apache Hadoop 文件系统 (HDFS)、Impala、Hive Iceberg 等进行数据仓储
- 用 DevOps 和 MLOps 推动人工智能训练和推理系统的工作流程
- 管理容器的 Kubernetes
- Apache Spark 图形处理
这些组件可从开源社区获取。
Supermicro Cloudera 与 Cloudera、开源软件和其他软件合作伙伴携手,为企业客户提供这些解决方案。Cloudera 集成软件组件,使其能够在平台上运行。 Supermicro Cloudera 为开发人员和客户提供系统级软件支持。Cloudera 将软件组件组织成易于管理的平台和模块,以便进行部署,并添加了数据溯源和数据安全功能。
Cloudera 整合了大量开源软件,将其组织成一个既可在内部运行又可在云中运行的平台,并提供企业级支持,帮助客户建立可扩展且可靠的数据收集、数据分析、ETL 和数据湖系统。此外,Cloudera 还增加了数据出处功能,以确保数据的可信度
Apache® Spark™、Kafka、Flink、Nifi、Iceberg、Hadoop 等开源软件带来了收集数据、分析数据、设计数据和存储数据的最新软件系统和架构。这些技术通过提供组织和管理数据的框架来简化和加速人工智能,以应对随时间发生的变化。开源软件提供了最新技术,而用户需要维护和支持他们的软件基础设施,除非他们使用由 Cloudera 等公司组织的软件。
资源






