Was ist Edge Computing?
Edge Computing ist ein dezentrales Rechenmodell, bei dem die Datenverarbeitung direkt am oder in der Nähe des Entstehungsortes erfolgt, anstatt die Daten an ein zentrales Rechenzentrum oder eine Cloud-Umgebung zu übertragen. Dieser Ansatz unterscheidet sich von traditionellen Rechenarchitekturen, die stark auf zentralisierter Verarbeitung basieren, die sich oft weit entfernt von den datenerzeugenden Geräten befindet.
In einem Edge-Computing-Framework finden Datenanalyse und Systemreaktion deutlich näher am Entstehungsort der Daten statt, sei es von IoT-Systemen, IoT-Edge-Sensoren oder industriellen Steuerungssystemen. Dieser lokale Ansatz ermöglicht es Systemen, autonomer zu arbeiten und Daten zu interpretieren und darauf zu reagieren, ohne auf eine ständige Kommunikation mit einer zentralen Cloud oder einem Rechenzentrum angewiesen zu sein.
Edge Computing ist eng mit dem Konzept des intelligenten Netzwerkrandes verbunden. Dabei verarbeiten und analysieren Geräte am Rand des Netzwerks Daten in Echtzeit und ermöglichen so intelligentere und schnellere Entscheidungen. Diese Anwendungen fallen häufig unter den Begriff IoT-Anwendungen , die lokale Rechenleistung für eine verbesserte Reaktionsfähigkeit nutzen.
Der Aufstieg des Edge Computing spiegelt den wachsenden Bedarf wider, die von verteilten Geräten generierten Datenmengen in Echtzeit zu verarbeiten. Da digitale Umgebungen immer komplexer und geografisch verteilter werden, stoßen herkömmliche zentralisierte Architekturen oft an ihre Grenzen hinsichtlich Leistung und Skalierbarkeit. Edge Computing begegnet dieser Herausforderung, indem es Rechenkapazität auf verschiedene Punkte im Netzwerk verteilt und so schnellere Erkenntnisse und ein adaptiveres Systemverhalten ermöglicht.
Dieses dezentrale Modell stellt einen grundlegenden Wandel in der Art und Weise dar, wie Unternehmen moderne Anwendungen entwickeln und bereitstellen. Anstatt alle Verarbeitungsprozesse an einem zentralen Ort zu bündeln, ermöglicht Edge Computing lokale Abläufe und unterstützt skalierbare, ausfallsichere Infrastrukturen branchenübergreifend – von der Fertigung und Logistik über das Gesundheitswesen bis hin zu Smart Cities. Dabei werden häufig Zwischensysteme wie IoT-Gateways eingesetzt, um Edge-Geräte mit größeren Netzwerken zu verbinden.
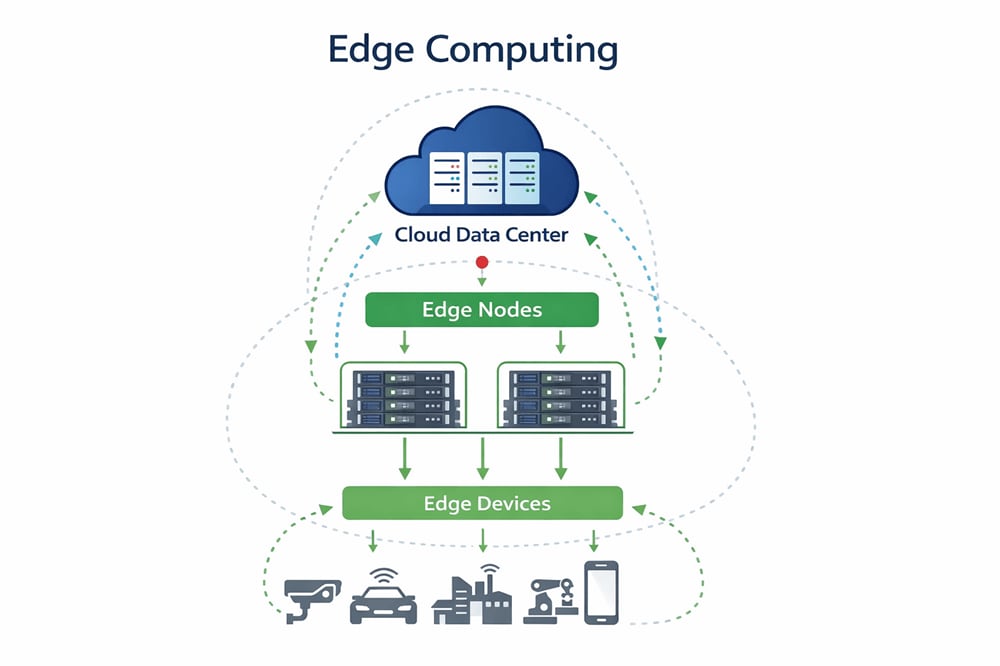
Wie Edge Computing funktioniert
Edge Computing funktioniert, indem wichtige Rechenaufgaben wie Datenanalyse und -verarbeitung von zentralen Rechenzentren an verteilte Standorte verlagert werden, die sich physisch näher am Entstehungsort der Daten befinden. Diese Verlagerung betrifft nicht nur die geografische Lage, sondern auch die Umstrukturierung der Architektur, um zeitkritische Vorgänge zu unterstützen, die Netzwerkabhängigkeit zu reduzieren und Echtzeit-Entscheidungen direkt an der Quelle zu ermöglichen. Edge-Umgebungen bestehen typischerweise aus einem mehrschichtigen System mit Edge-Geräten, lokalen Rechenknoten und Netzwerkkomponenten, die bei Bedarf mit zentralen Systemen kommunizieren.
Fortschrittliche Embedded-Serverlösungen spielen eine entscheidende Rolle im Bereich Edge Computing. Diese Server sind auf Energieeffizienz bei gleichzeitig hoher Leistung ausgelegt und erfüllen die anspruchsvollen Anforderungen von Edge-Computing-Aufgaben. Im Sinne von Green Computing zielen diese Lösungen darauf ab, die Umweltbelastung zu minimieren. Dies erreichen sie durch die Reduzierung des CO₂-Fußabdrucks bei gleichzeitiger Maximierung der Betriebseffizienz.
Ebenso wichtig ist, dass diese Serverlösungen für den zuverlässigen Betrieb unter anspruchsvollen Umgebungsbedingungen ausgelegt sind. Dies gewährleistet eine gleichbleibende Leistung in unterschiedlichsten Umgebungen, auch bei extremen Temperaturen oder anderen hohen Betriebsanforderungen. Dank ihrer Vielseitigkeit und Ausfallsicherheit eignen sich diese Server ideal für eine breite Palette von Edge-Computing-Anwendungen.
Edge-Computing-Systeme werden typischerweise auch mit Blick auf erhöhte Sicherheit entwickelt, da sie häufig sensible Daten außerhalb traditioneller IT-Perimeter verarbeiten. Lokale Sicherheitskontrollen, Verschlüsselung und Systemhärtung sind unerlässlich, um die Integrität und Vertraulichkeit der am Netzwerkrand verarbeiteten Daten zu gewährleisten.
Durch den Einsatz von Rechenleistung näher am Ort der Datenerzeugung ermöglicht Edge Computing schnellere Verarbeitungszeiten, reduziert die Belastung der Netzwerkbandbreite und verbessert die Reaktionsfähigkeit digitaler Dienste und Geräte.
Edge-Computing vs. Cloud-Computing vs. Fog-Computing
Edge-, Cloud- und Fog-Computing beziehen sich zwar alle auf die Art und Weise und den Ort der Datenverarbeitung, stellen aber jeweils einen eigenen Ansatz für die Rechnerarchitektur mit unterschiedlichen Anwendungsbereichen und Leistungsmerkmalen dar.
Cloud Computing basiert auf zentralisierten Rechenzentren, die sich oft weit entfernt vom Ort der Datenerzeugung befinden. In diesem Modell werden Daten über ein Netzwerk (typischerweise das Internet) übertragen und von Cloud-Service-Anbietern verarbeitet, gespeichert und verwaltet. Dieser Ansatz bietet Skalierbarkeit und zentrale Kontrolle, kann aber insbesondere bei Echtzeit- oder datenintensiven Anwendungen zu Latenz- und Bandbreitenbeschränkungen führen.
Im Gegensatz dazu verarbeitet Edge Computing Daten lokal, also in der Nähe ihrer Quelle. Dieses Modell verkürzt die Datenübertragungswege und minimiert die Latenz, indem es Informationen direkt auf dem Endgerät oder einem nahegelegenen Edge-Knoten analysiert. Es eignet sich besonders für Anwendungsfälle, die sofortige Erkenntnisse oder Maßnahmen erfordern, wie beispielsweise autonome Systeme, industrielle Automatisierung oder Videoanalyse vor Ort.
Fog Computing fungiert als Bindeglied zwischen Edge- und Cloud-Umgebungen. Es erweitert die Cloud-Funktionen näher an den Netzwerkrand, indem es eine Schicht verteilten Rechnens einführt, die zwischen lokalen Geräten und der zentralen Cloud-Infrastruktur arbeitet. Fog Computing hilft bei der Bewältigung von Aufgaben, die für Edge-Geräte zu ressourcenintensiv, für die reine Cloud-Verarbeitung aber zu latenzempfindlich sind.
Im Wesentlichen ist Cloud Computing zentralisiert, Edge Computing vollständig dezentralisiert und Fog Computing bietet einen hybriden Ansatz. Jedes Modell hat seine Berechtigung, abhängig von den spezifischen Anforderungen an Geschwindigkeit, Bandbreite, Datensouveränität und Rechenleistung.
Wichtigste Vorteile des Edge Computing
Edge Computing bietet zahlreiche strategische und operative Vorteile, die es zu einer überzeugenden Architektur für moderne datenintensive Anwendungen machen.
Einer der größten Vorteile ist die reduzierte Latenz. Durch die direkte Datenverarbeitung am oder nahe dem Ursprungsort entfällt beim Edge Computing die Notwendigkeit, Informationen über große Entfernungen an zentrale Systeme zu übertragen. Dies verkürzt die Reaktionszeiten drastisch, was für Echtzeitanwendungen wie autonome Fahrzeuge, Augmented Reality, industrielle Automatisierung und Ferndiagnose in der Telemedizin entscheidend ist.
Ein weiterer entscheidender Vorteil ist die Bandbreiteneffizienz. Die lokale Datenverarbeitung ermöglicht es Systemen, Daten zu filtern, zu analysieren und darauf zu reagieren, bevor nur die wichtigsten Informationen an zentrale Cloud-Plattformen übertragen werden. Dadurch wird das über das Netzwerk gesendete Datenvolumen minimiert, was die Bandbreitennutzung und die damit verbundenen Kosten reduziert – besonders wertvoll in Umgebungen mit begrenzter oder teurer Konnektivität.
Verbesserte Sicherheit und Datenschutz sind ebenfalls systembedingte Vorteile von Edge Computing. Die Datenverarbeitung vor Ort oder innerhalb der lokalen Infrastruktur reduziert die Gefährdung sensibler Informationen während der Übertragung. Dies kann das Risiko des Abfangens oder unbefugten Zugriffs verringern, insbesondere in Branchen mit strengen regulatorischen Anforderungen wie dem Gesundheitswesen, dem Finanzsektor und der kritischen Infrastruktur.
Schließlich trägt Edge Computing zu einer höheren Systemzuverlässigkeit bei. Da Edge-Geräte und -Knoten unabhängig von der zentralen Cloud arbeiten können, bleibt ihre Funktionsfähigkeit auch bei Netzwerkstörungen oder -ausfällen erhalten. Diese lokale Ausfallsicherheit gewährleistet die Kontinuität des Dienstes, selbst wenn die Verbindung zur zentralen Infrastruktur vorübergehend unterbrochen ist.
Diese kombinierten Vorteile machen Edge Computing zu einem leistungsstarken Ansatz für Organisationen, die ihre Performance steigern, operative Risiken reduzieren und verteilte Umgebungen besser unterstützen wollen.
Anwendungsfälle und Anwendungen
Edge Computing ermöglicht die Verarbeitung von Daten vor Ort oder in unmittelbarer Nähe, was für Branchen, die schnelle Entscheidungen und lokale Steuerung erfordern, unerlässlich geworden ist. Die Möglichkeit, Rechenleistung näher an den Ort der Datenerzeugung zu bringen, hat neue Innovationspotenziale eröffnet, insbesondere in Umgebungen, in denen Latenz, Zuverlässigkeit und Reaktionsfähigkeit entscheidend sind.
In der Fertigung ermöglicht Edge Computing vorausschauende Wartung, Echtzeit-Qualitätskontrolle und Produktionsoptimierung durch die direkte Analyse von Sensordaten in der Produktionshalle. Gesundheitssysteme nutzen Edge-Technologien für Ferndiagnose, Patientenüberwachung und medizinische Bildgebung in Umgebungen, in denen geringe Latenzzeiten entscheidend sind. Im Einzelhandel unterstützt die Edge-Infrastruktur intelligente Kassensysteme, personalisierte Kundenerlebnisse und effizientes Bestandsmanagement durch die lokale Datenverarbeitung in den Filialen.
Autonome Fahrzeuge sind stark auf Edge-Computing angewiesen, um Sensordaten auszuwerten, Fahrentscheidungen zu treffen und mit der umliegenden Infrastruktur zu kommunizieren. Dies geschieht in Echtzeit und ohne ständige Cloud-Verbindung. Auch Smart-City-Initiativen nutzen Edge-Technologien, um Verkehrssysteme zu steuern, die öffentliche Sicherheitsinfrastruktur zu überwachen und den Energieverbrauch lokal zu optimieren.
Edge Computing ist eng mit dem Ausbau von IoT-Edge-Lösungen verknüpft, bei denen Daten auf oder in der Nähe von vernetzten Geräten verarbeitet werden. Diese Anwendungen sind vielfältig und wachsen stetig; ihre technischen Unterschiede werden ausführlicher auf einer separaten Glossarseite zum Thema IoT Edge erläutert.
Als zentrale Voraussetzung für verteiltes Rechnen ermöglicht Edge-Architektur Unternehmen, ihre IT-Kapazitäten in die physische Welt auszudehnen und so schnellere Entscheidungen, robustere Systeme und skalierbare Bereitstellungsmodelle zu unterstützen. Von der Industrieautomation über die vernetzte Gesundheitsversorgung bis hin zu intelligenten Transportsystemen spielt Edge-Computing eine entscheidende Rolle beim Aufbau schneller, effizienter und anpassungsfähiger digitaler Ökosysteme in modernen Unternehmen.
Herausforderungen und Überlegungen
Edge Computing bietet zwar klare Vorteile in Bezug auf Geschwindigkeit, Skalierbarkeit und Effizienz, bringt aber auch eine Reihe einzigartiger Herausforderungen mit sich, denen sich Unternehmen stellen müssen, um eine erfolgreiche Implementierung und einen reibungslosen Betrieb zu gewährleisten.
Eine der wichtigsten Herausforderungen ist die Komplexität des Managements. Da die IT-Ressourcen über mehrere Standorte verteilt sind, wird die Aufrechterhaltung einheitlicher Leistungs-, Sicherheits- und Konfigurationsstandards zunehmend schwieriger. Dies gilt insbesondere für abgelegene oder räumlich eingeschränkte Umgebungen. Um dem entgegenzuwirken, müssen IT-Teams eine Vielzahl von Hardware-, Software- und Netzwerkkomponenten an diesen dezentralen Standorten verwalten.
Sicherheit und Datenschutz sind ebenfalls von entscheidender Bedeutung. Zwar kann die lokale Datenverarbeitung das Risiko bei der Übertragung verringern, doch sind Edge-Geräte und -Knoten unter Umständen leichter zugänglich oder operieren außerhalb der üblichen Sicherheitsvorkehrungen von Unternehmen. Dies erhöht den Bedarf an robustem Endpunktschutz, sicheren Startprozessen und Echtzeitüberwachung, um unbefugten Zugriff oder Manipulationen zu verhindern.
Interoperabilität und Standardisierung stellen eine weitere Herausforderung dar. Edge-Umgebungen umfassen oft eine Vielzahl von Geräten, Plattformen und Protokollen. Die Gewährleistung der Kompatibilität dieser Komponenten, insbesondere in Umgebungen mit unterschiedlichen Anbietern oder in Legacy-Systemen, kann sowohl die Integrationsbemühungen als auch die langfristige Skalierbarkeit beeinträchtigen.
Darüber hinaus können die Infrastrukturkosten erheblich sein. Edge Computing entlastet zwar zentrale Rechenzentren, doch die Bereitstellung und Wartung von Edge-Hardware in großem Umfang erfordert Investitionen in robuste Systeme, zuverlässige Stromversorgung und sichere Verbindungen. Der Return on Investment hängt stark vom Anwendungsfall, dem Umfang der Bereitstellung und der Betriebsstrategie ab.
Schließlich müssen Unternehmen den Datenlebenszyklus am Netzwerkrand berücksichtigen. Entscheidungen darüber, welche Daten lokal verarbeitet, welche verworfen und welche zur Langzeitspeicherung oder Analyse in die Cloud übertragen werden, erfordern sorgfältige Planung und die konsequente Umsetzung von Richtlinien, um Leistung mit regulatorischen und geschäftlichen Anforderungen in Einklang zu bringen.
Schlüsselbegriffe im Edge Computing
Das Verständnis der Kernkomponenten von Edge Computing ist unerlässlich, um die Funktionsweise verteilter Architekturen zu begreifen. Im Folgenden werden einige wichtige Begriffe erläutert, die häufig mit Edge-Umgebungen in Verbindung gebracht werden:
Kantenknoten
Ein Edge-Knoten ist ein lokaler Rechenendpunkt, der Daten verarbeitet oder weiterleitet, die von Geräten in der Nähe erzeugt werden. Er dient typischerweise als erste Verarbeitungsschicht in der Edge-Computing-Hierarchie und ermöglicht so die Echtzeit-Datenfilterung oder Entscheidungsfindung näher an der Quelle.
Tor
Ein Gateway fungiert als Brücke zwischen Endgeräten und zentralen Netzwerken oder Systemen. Es verwaltet den Datenverkehr, übernimmt die Protokollübersetzung und führt häufig grundlegende Verarbeitungs- oder Sicherheitsaufgaben durch, bevor es Daten an Upstream- oder Downstream-Netzwerke weiterleitet.
Mikro-Rechenzentrum
Mikro-Rechenzentren sind kompakte, in sich geschlossene Einrichtungen, die Rechen-, Speicher- und Netzwerkressourcen in der Nähe des Einsatzortes bereitstellen. Sie unterstützen spezifische Anwendungen oder lokale Arbeitslasten und reduzieren so die Notwendigkeit, Daten an entfernte Rechenzentren zu senden.
Edge-Gerät
Ein Edge-Gerät ist ein beliebiger Endpunkt, wie beispielsweise ein Sensor, eine Kamera oder eine industrielle Steuerung, der Daten innerhalb einer Edge-Computing-Umgebung erzeugt oder verarbeitet. Diese Geräte verfügen oft über eine begrenzte Rechenleistung, um Echtzeitreaktionen zu ermöglichen.
Edge Orchestrator
Ein Edge-Orchestrator ist eine Softwareschicht oder Plattform, die Workloads auf mehreren Edge-Knoten verwaltet, bereitstellt und überwacht. Er ermöglicht die zentrale Steuerung dezentraler Infrastruktur und trägt so zur Aufrechterhaltung von Konsistenz und Skalierbarkeit bei.
Latenz
Im Edge Computing bezeichnet Latenz die Verzögerung zwischen der Datenerzeugung und der Verarbeitung oder Nutzung der Daten. Die Reduzierung der Latenz ist eines der Hauptziele der Platzierung von Rechenressourcen näher an der Datenquelle.
Echtzeitverarbeitung
Dieser Begriff beschreibt die Fähigkeit eines Systems, Daten innerhalb von Millisekunden zu erfassen, zu analysieren und darauf zu reagieren. Edge Computing unterstützt Echtzeitverarbeitung, indem es Übertragungsverzögerungen minimiert und sofortige lokale Berechnungen ermöglicht.
Häufig gestellte Fragen
- Worin besteht der Unterschied zwischen Edge Computing und Cloud Computing?
Obwohl sowohl Edge- als auch Cloud-Computing Datenspeicherung und -verarbeitung beinhalten, liegt der Hauptunterschied im Standort. Cloud-Computing zentralisiert die Verarbeitung in großen Rechenzentren, die oft weit von den Endnutzern entfernt sind. Edge-Computing hingegen verarbeitet Daten näher an ihrem Entstehungsort. - Wie verbessert Edge Computing das IoT?
Edge Computing ergänzt das IoT, indem es Geräten ermöglicht, Daten lokal zu verarbeiten und zu analysieren, anstatt sie zur Verarbeitung an eine zentrale Cloud zu senden. Dies ermöglicht schnellere Entscheidungen – ein entscheidender Vorteil für zeitkritische Anwendungen wie die industrielle Automatisierung, Smart Cities oder autonome Systeme. - Ist Edge Computing sicherer als Cloud Computing?
Edge Computing kann Datenschutz und Datensicherheit verbessern, indem es die Übertragungswege sensibler Daten verkürzt und so das Risiko während der Übertragung reduziert. Gleichzeitig entstehen jedoch neue Sicherheitsherausforderungen, beispielsweise die Verwaltung einer großen Anzahl verteilter Endpunkte. Sowohl Edge- als auch Cloud-Umgebungen erfordern umfassende, kontextspezifische Sicherheitsstrategien. - Warum ist Edge Computing für 5G wichtig?
Edge-Computing ist für 5G-Netze unerlässlich, da es die Latenz verringert. Da 5G eine schnellere Datenübertragung ermöglicht, stellt die Edge-Infrastruktur sicher, dass die Verarbeitung mithalten kann, insbesondere bei mobilen und bandbreitenintensiven Anwendungen. - Was sind Beispiele für Edge Computing im realen Leben?
Beispiele für Edge Computing aus der Praxis sind autonome Fahrzeuge, die Sensordaten in Echtzeit verarbeiten, Einzelhandelsgeschäfte, die In-Store-Analysen zur Kundenverhaltensanalyse nutzen, und Industrieanlagen, die vorausschauende Wartungssysteme in ihren Produktionshallen einsetzen. Diese Szenarien erfordern eine sofortige Datenverarbeitung ohne Abhängigkeit von entfernten Rechenzentren.